
Part 1: How to work with SQL queries as a pro
🛠 CI/CD, Git, Version Control and Creating your first Pull Request


As data analysts and BI developers, we frequently work with SQL, which is both a powerful tool and a programming language in its own right. And like any other programming language, SQL should be treated with an engineering mindset to ensure effective development. There will be 2 parts on this topic. Subscribe so you don’t miss the next one tomorrow!
Did you ever look at code thinking, "Ew, brother, ew! What's that?" Probably it wasn't written by you, but there's also a chance it was your own code from a couple of years ago. High standards of code quality and consistency are crucial for any data organization. This is especially true for SQL, where a single poorly written query can lead to significant performance issues or even critical failures.
To dive deeper into this, I've invited Dmitry Anoshin, an experienced data engineer and creator of Surfalytics community, to share his experience and best practices on how to work with SQL in a more efficient way.
Dmitry will cover key concepts like code review, pull requests, and CI/CD, and show us real-life examples of how these practices are implemented. Since our focus is SQL, we’ll also explore SQL code formatting in depth.
Additionally, we’ll discuss why pre-commit linting is one of the best practices for maintaining high-quality SQL code. This session aims to equip us with the knowledge to handle SQL more efficiently and maintain robust development practices.
Without CI/CD
Let’s check how typical organization querying the data. Imagine there is a startup, for example focusing on building and selling dog collars with GPS.
Assume, they are using WooCommerce and Wordpress as their online store and all sales data is available in this OLTP database that serves as a backend for online store.
Founders might have the questions about sales patterns and want to query the data using direct access to a database from SQL Client. It could be free Dbeaver or $ DataGrip (really like to work with it). After some time, the team come up with the SQL queries that are returning the Sales, Orders, Shipping information and more or less answer some business questions.
Let’s assume, they have just 3 SQL queries and carefully save them in Google Drive:
sales.sqlorders_shipping.sqlpartners_orders.sql

It is probably a Single Source of Truth. The team is small and everyone knows how to COPY-PASTE these queries and get desired numbers.
At the same time, the collar itself is a piece of art and like apple watch for dogs, it is collecting lots of data points about wellbeing of the dogs and backend team built a dedicated database with collar, user, dog and etc. activities.
In case someone wants to know more specific details about firmware version, mobile app version, usage pattern or even distinct list of dog breeds and their names, they definitely have to use the SQL queries. And backend team was helpful to prepare queries:
active_pets.sqlcollars_firmware_activity_breakdown.sqlusers_pets_collars_stat.sql
Company is growing and integrated new systems, for example for Shipping and Returns, Customer Support and some other useful services. As you can guess more queries were generated…
At some point company decide to find dedicated person to handle the analytics and provide insights to the business. Company just hired two Data Analysts who are strong with asking right business questions and provide valuable business recommendations and support it with DATA, yay!
Now, fun begins.
Analysts started to copy SQLs from Google Drive and start to do little modifications. Sometimes they saved it back, sometimes not. Sometimes they modify the same file at the same time. Someone likes CamelCase, someone snake_case. They also didn’t agree what to use TAB or 4 spaces for tabulation. Oh, and of course debating about UPPER CASE vs LOWER CASE…
After a while google drive became something like (just based on a single file):
sales_v1.sqlsales_v2.sqlsales_v2_latest.sqlsales_v3_by_analyst_1.sqlsales_v5.1.sqletc.

It looks fun but in reality it is a problem. In first order it is a problem for our founders and business owners. While analysts experimenting with there best format, naming conventions and so on, they basically adding complexity on cognitive load. Moreover, this is risky, because now single source of truth = head of analyst(s).
I didn’t mention Data Warehouse, BI, ETL and other modern practices for a reason to make this text simpler and to the point. But all the same problem are existing with Data Warehouse/Data Lake/LakeHouse.
Version control
The simple solution that will help to solve the SQL files version and keep a single file is using Version Control System (VCS) such as git . There are many vendors offering their solutions:
GitHub
GitLab
Azure DevOps
and etc.
If you don’t know where to start, use GitHub. You will find lots of examples.
The first step for our rock data team would be consolidate SQL queries together and push them into Repository.
Git like system gives lots of benefits for data team:
Storing all code in a single place that available for anyone to review
readme.mdfiles will guide everyone in the folder and explain anythingTrack all changes and versions
Do a code review with the team and cross teams
Enforcing quality and standards with
.pre-commit, Continuous Integrations (CI) and Continuous Deployments (CD).
This might sound like complicated topic from Software Engineering and DevOps world. But it is not that complicated and as usual, you have to start small.
Let’s break down each point and review together.

How to open a pull request
Example with GitHub Web version
Create a new branch (copy of production code)
A branch in Git is like a separate workspace where you can make changes to a project without affecting the “main” version. Think of it as a copy of the project where you can experiment, add new features, or fix bugs. We’ll cover this in the code review process.

Switch to the new branch and find the file you want to edit and click on editing it
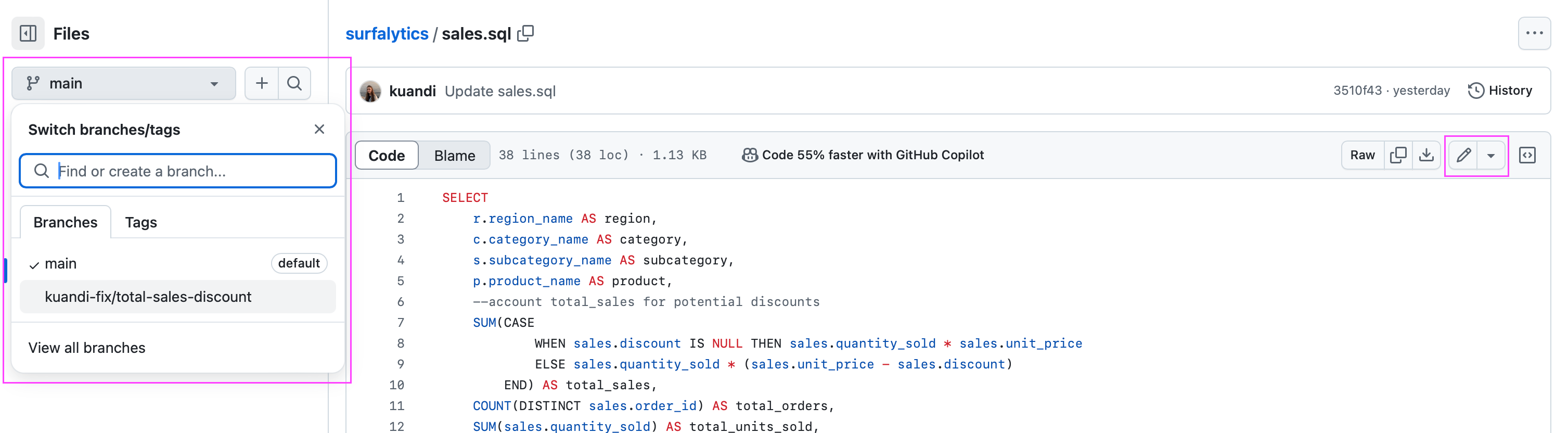
Apply changes directly in the file and Commit changes

Add a commit message and description. Depending on the organization, you might have specific rules for commit messages and branch names. Always commit to a new branch.

Open a pull request
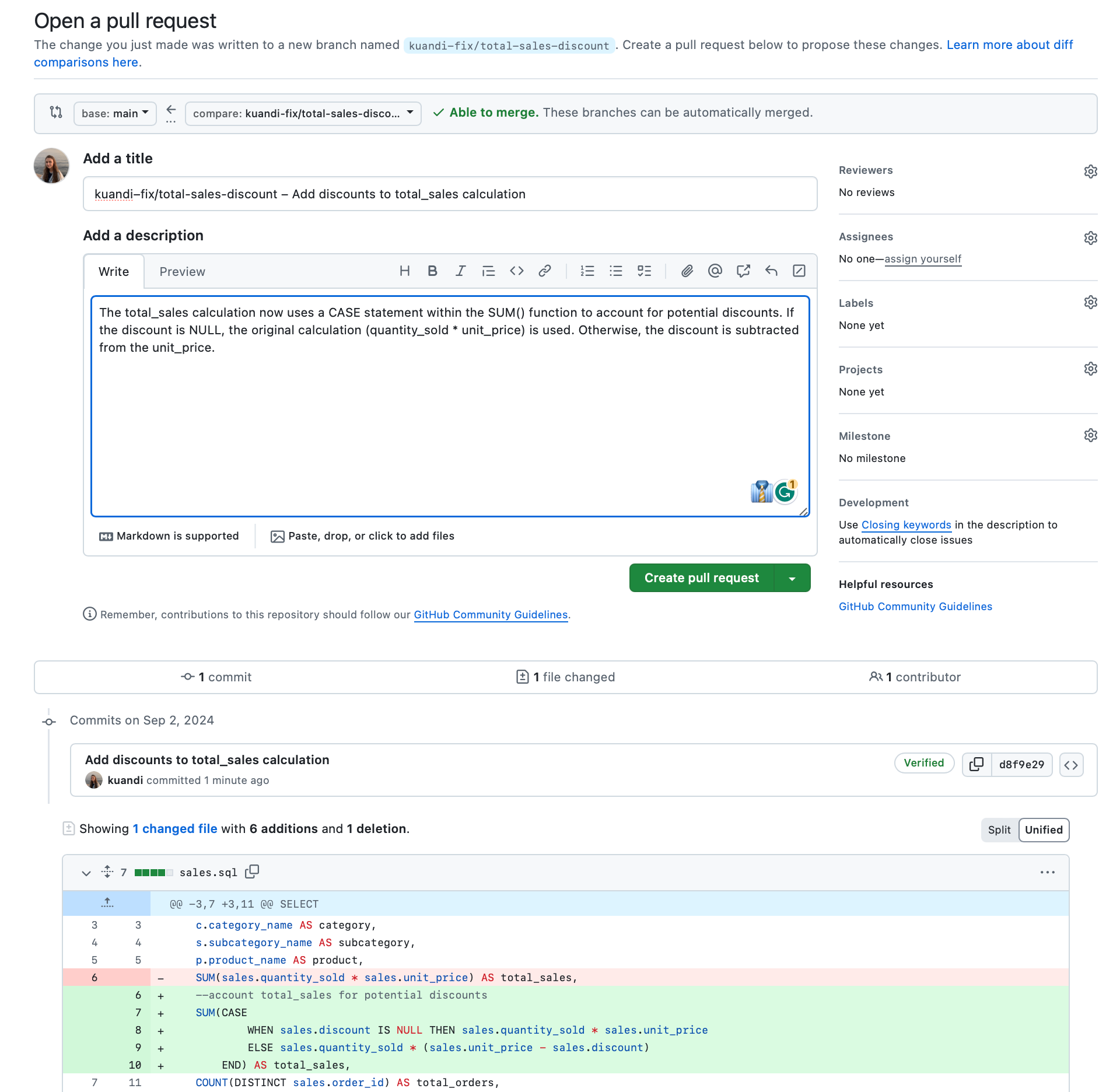
Merge pull request. Better do it after code review (we’ll talk about this later).

But usually this happening in local IDE such as VSCode. You can learn more about this in these lessons:
💡 Check out Best Practices for Branch Naming and Commit Messages
 | A guest post by
|